Welcome to our GitHub page! You will find here a review of our work.
Our team is composed by:
 |
 |
 |
|---|---|---|
| Mattia LECCI | Aude RAZAFIMBELO | Paolo TESTOLINA |
The goal of our work is to classify dogs images according to their breeds. To do so, we tried different architectures, techniques and optimizations as presented in the following sections.
Architectures
In order to start working directly on the Neural Network specific code, we used already existing code from Kaggle (MNIST starter code). This allowed us to learn more quickly without wasting time on image loading, encodings and language specific problems that may arise for python newbies.
MNIST Architecture
The CNN is composed by the following layers:
- Conv2D(32)
- Batch Normalization
- ReLU
- Conv2D(32,ReLU)
- Max Pooling
- Batch Normalization
- Conv2D(64)
- Batch Normalization
- ReLU
- Conv2D(64,ReLU)
- Max Pooling
- Flatten
- Batch Normalization
- Dense(512)
- Batch Normalization
- ReLU
- Dense(120,softmax)
During the optimization processes dropout was inserted between some layers, optimizing on the number of dropout layers and the dropout probability. With this model we were able to obtain acc=15%, val_acc=5%.
After using an Adam optimizer and adding 2 dropouts in the middle of the network we were able to obtain up to acc=22%, val_acc=12%. (NewModel_best_run)
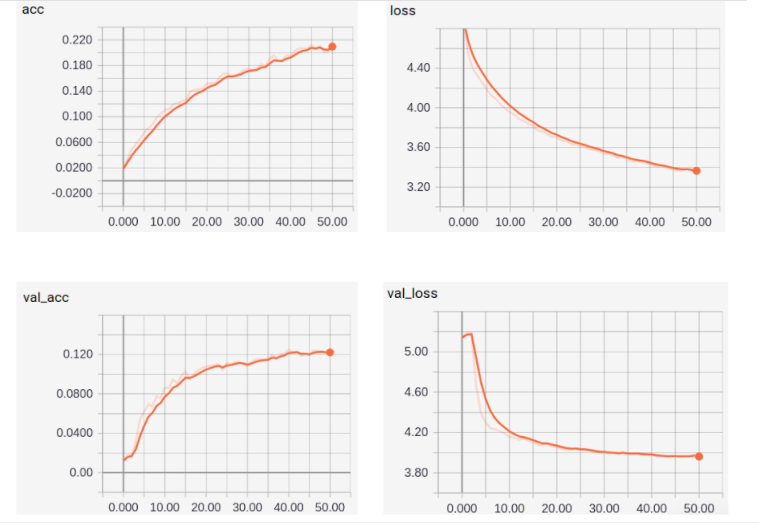
Binary Classification Architecture
We looked into a CNN that classifies cats and dogs with great accuracy (over 95%). We tried to adapt it to multiclass classification but its performance was poor, probably due to the far more complicated problem. We also tried to look into a direct extension of many binary classifiers into a single multiclass one, but what we found out was far too complicated to be implemented in this project (Erin L. Allwein, Robert E. Schapire, Yoram Singer. “Reducing Multiclass to Binary: A Unifying Approach for Margin Classifiers.”. Journal of Machine Learning Research.).
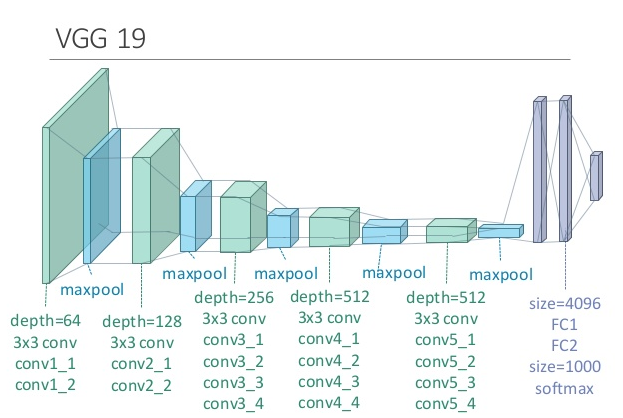
Transfer learning: VGG19
As a second baseline, we used a Transfer Learning technique based on Keras VGG19 starter. Again, to avoid wasting time on language specific problems, we just copied most of the code modifying only the interesting parts.
The main modifications were:
- Using the image-net pre-trained weights for VGG19
- Adding as output layers Dense(1024,ReLU), Dense(512,ReLU), Dense(120,softmax)
- Using fit_generator instead of fit
- Using an ImageDataGenerator to perform random transformations on input images (Data Augmentation)
We then otpimize the architecture in many different ways:
-
We started by optimizing the dropout probability right before our new top layer, choosing the best optimizer (sgd,adam,rmsprop) and choosing the best batch size (16,32,64,128,256).
-
Then, finding that Adam performed best, we tried to optimize its parameters (learning rate, beta_1, beta_2, decay).
-
We also tried to optimize SGD’s parameters to see how it performs. Result: way worse than Adam. Probably it’s simplicity is not adequate for this problem.
-
Since overfitting was still an issue, we optimized again with a higher dropout probability, adding a variable number of output layers (0,1,2), unfreezing some of the last few layers of VGG19 and, again, on the batch size (16,64,256).
-
Lastly, we added an extra Dense(2048,ReLU) right after the flattening. We optimized over the kernel regularization of this layer (lambda parameter) and adding or not an extra bottleneck layer (a Dense(100,ReLU) between Dense(2048) and Dense(1024)).
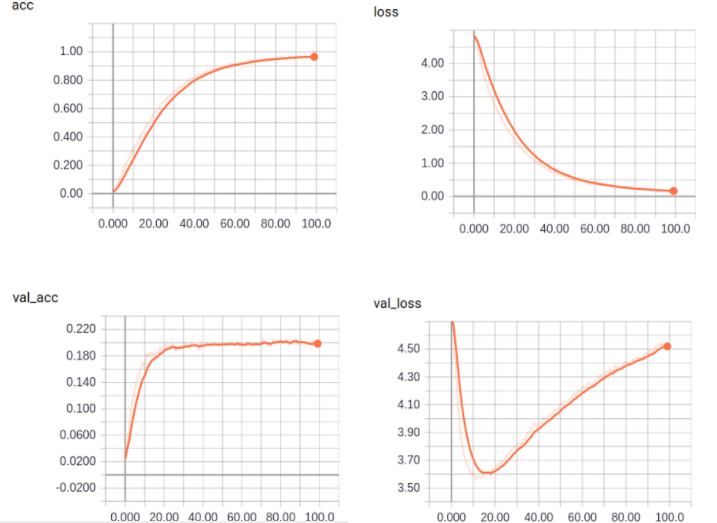
We saw that in general VGG19 tended to overfit a lot, hence it required some regularization techniques. At the end, though, it improved over the results from the blank MNIST example architecture but not much. It was able to obtain up to val_acc=17%. It is possible that to avoid the overfitting problem, the regularization needed was enough to reduce the model’s performance.
We report here an example of clearly overfitted run:
Transfer learning: VGG16
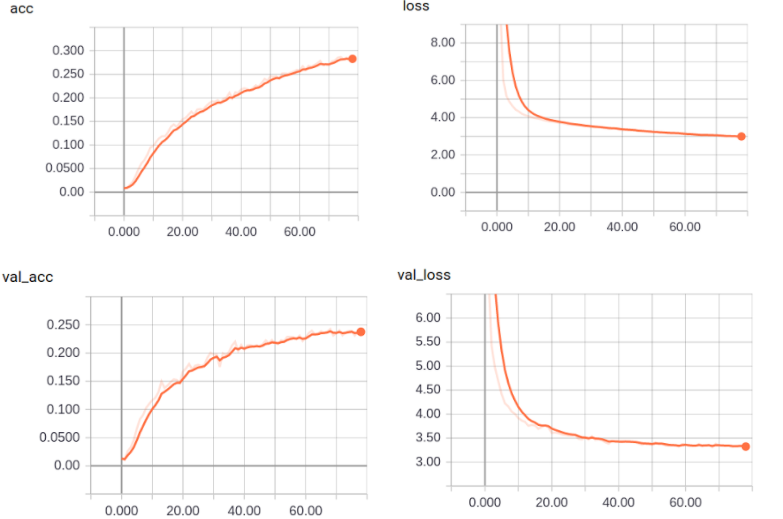
We’ve replicated what we’ve done with VGG19 with other pretrained models. The first, obvious, choice was its little brother VGG16. It’s basically the same model but with 3 missing layers. We hoped that a simpler architecture would yield less overfitting problems.
This was in fact the case! Not only that, but with less overfitting control techniques we avoided crippling the real performance of the model obtaining far better results: up to acc=28%, val_acc=24%!
Transfer learning: Xception
One last model that we tried was Xception. This is a tensorflow based model using a technique called Depthwise Separable Convolution.
The particular thing about this model is that, althought it’s a very deep network (much deeper than VGG16/19), the file containing its weight weighs only a fifth of those from the VGG family. This is due to its unique architecture.
Anyway, we optimized this model less than the other since its first run yielded quite unsatisfactory results: val_acc=15% with no overfitting. Since it’s only slightly better than the MNIST architecture and worse than both VGG19 and VGG16, we decided to abandon it quite soon.
What we learned from the project
Since we all come from a telecommunication background, we are not expert programmers nor have much experience with Machine Learning-related topics.
Hence, we learned quite a lot from this project, and not only about Deep Learning!
Some transversal knowledge and skills that we learned are:
- Setting up and accessing remote virtual machines
- Accessing and using basic Google Cloud instances
- Increased confidence with linux’ terminal
- First experience with Git/Github
- First steps with a new programming language: Python
- First experience with Jupyter Notebooks
- Studying research papers and obtain implementable code from them
More Deep Learning related knowledge, instead, was:
- Creating Neural Networks from scratch using Keras
- Manipulating existing architectures
- Reading results (distinguishing between training and validation)
- Methods to avoid overfitting
- Hyperparameter optimization
- Operating with callbacks
- Operating with Tensorboard
As we were beginners in Neural Network, we can now assume that we have gained some basics (and something more!).
More information
Here are the Slides of our presentation, that provide further information.
Notes
Due to the many connectin problems that we had with Google Drive (as mentioned in the slides), a lot of the notebooks contain errors at the end. They are usually the notebooks that we let run overnight for many hours and when trying to save or evaluating the performance of the best model they crashed. The good thing, though, is that the training/optimization verbose outuputs were correctly saved.