Reproducing a paper for the ICLR ‘19 challenge





Universitat Politècnica de Catalunya
R.Challenge
One of the challenges in machine learning research is to ensure that published results are reliable and reproducible. In support of this, this challenge has been set up in order to investigate the reproducibility of empirical results submitted to the 2019 International Conference on Learning Representations (ICLR).
The paper that we chose can be found here and its abstract is showed below:
Despite recent progress, Generative Adversarial Networks (GANs) still suffer from training instability, requiring careful consideration of architecture design choices and hyper-parameter tuning. The reason for this fragile training behaviour is partially due to the discriminator performing well very quickly; its loss converges to zero, providing no reliable backpropagation signal to the generator. In this work we introduce a new technique - progressive augmentation of GANs (PAGAN) - that helps to overcome this fundamental limitation and improve the overall stability of GAN training. The key idea is to gradually increase the task difficulty of the discriminator by progressively augmenting its input space, thus enabling continuous learning of the generator. We show that the proposed progressive augmentation preserves the original GAN objective, does not bias the optimality of the discriminator and encourages the healthy competition between the generator and discriminator, leading to a better-performing generator. We experimentally demonstrate the effectiveness of the proposed approach on multiple benchmarks (MNIST, Fashion-MNIST, CIFAR10, CELEBA) for the image generation task.
Model
In this work a novel method has been proposed - progressive augmentation (PA) - in order to improve the stability of GANs training, and showed a way to integrate it into existing GAN architectures with minimal changes.
The discriminator learning faster than then generator leads to GAN instability. Hence, PA focuses on making harder the learning task of the discriminator by augmenting progressively its input space with an arbitrary long random bit sequence s.
The class of the augmented sample (x,s) is then set based on the combination x with s (XOR function), resulting in real and generated samples contained in both true and fake classes, thus, making the learning task more challenging as it can be seen in the next figure.
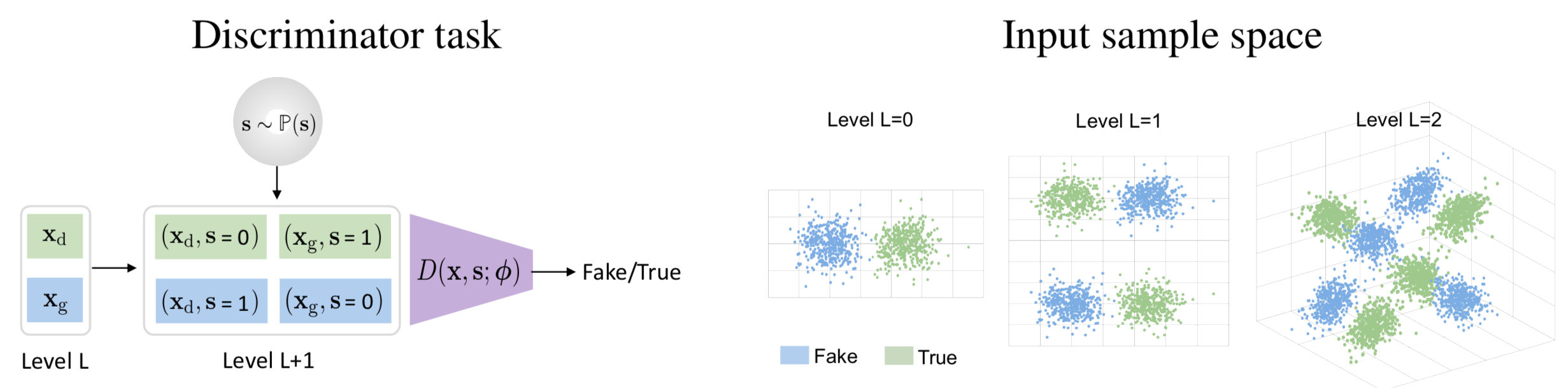
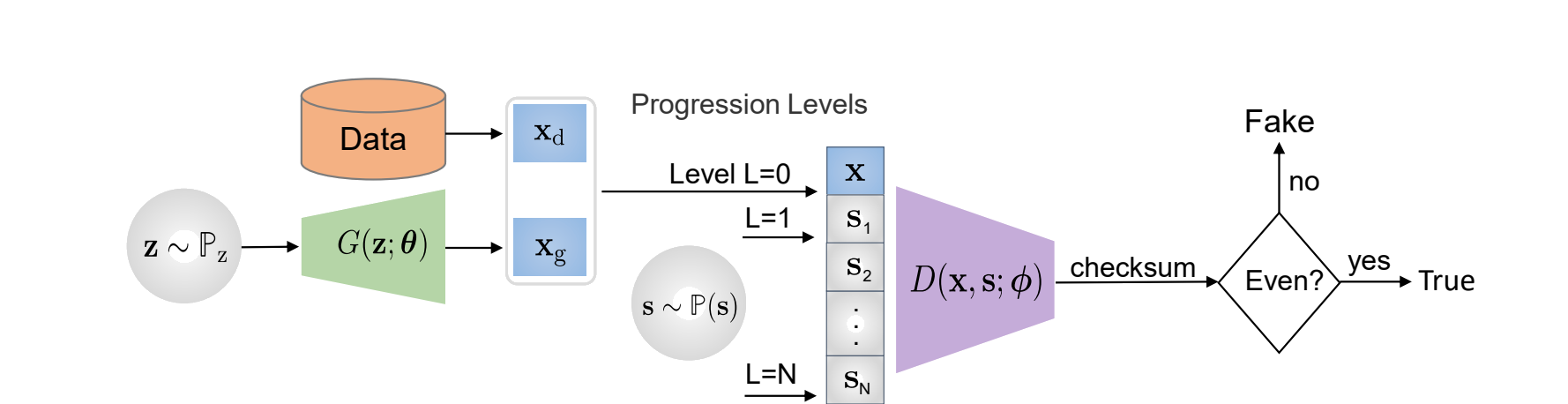
Also, in the following figure, it is shown the architecture that is was used for this project, based on the generator and the discriminator of the SN-DCGAN and the progressive augmentation module in between.
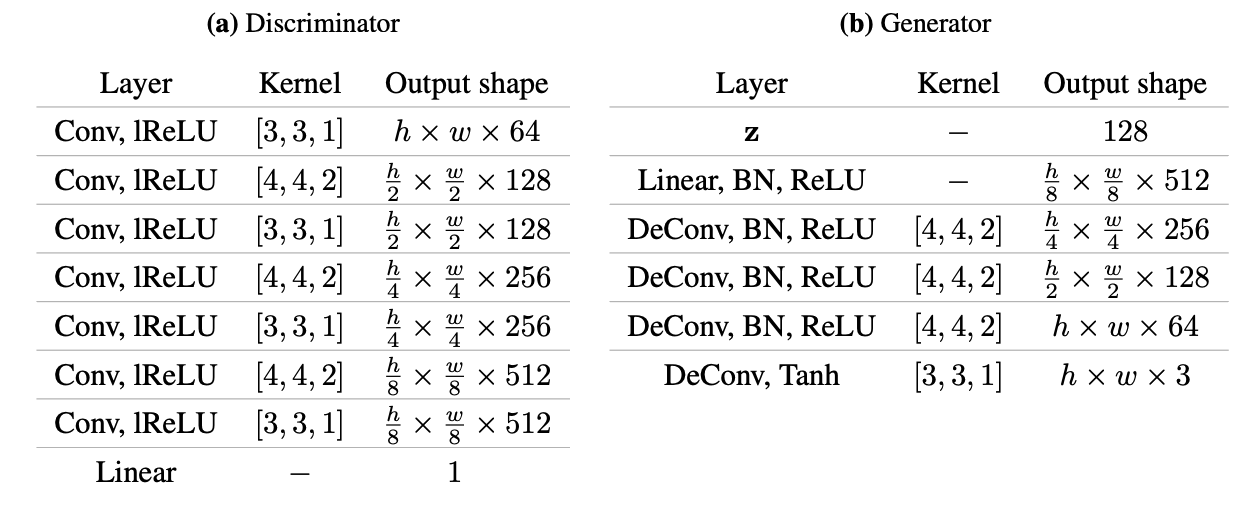
The specifications of the GAN network are shown in tables a) and b).
Approach
In this section we intent to explain in detail the work that we have been doing in order to achieve the main goal, which was to reproduce the paper.
The first thing we did was to study the paper individually for a one week period time. In that way, we would be able to share the main concepts and doubts in the first scheduled meeting.
Once we thought we have understood the paper, we started working towards a baseline. Thus, we wanted to implement it in order to be able to compare our results in the future. The baseline was a SN-DCGAN (spectral normalized deep convolutional general adversarial network ), and after researching, we found a github repository which implemented a simple DCGAN (we were still missing the SN part). This model was implemented in Tensorflow.
In order to add the SN to the baseline, we used a part of the code of an already implemented SN-GAN github repository.
The metrics that were used in the paper to evaluate the performance of the system were mainly two: Kernel Inception Distance (KID) and Fréchet Inception Distance (FID). It was also necessary to implement them.
We found a code that allowed us to implement the KID. However, it was really difficulty to adapt it with our code and we decided to implement it ourselves by just using pre-trained Keras inception network and writing the algorithm by numpy library.
At the same time, we were implementing progressive augmentation (PA), the key point of the whole paper. This lead to some difficulties when trying to modify the model when adding a channel to the input space and first convolutional layer of the discriminator. This was because Tensorflow uses a static graph and so it makes it very hard to modify the system during runtime. At this point, we decided to change our framework to Pytorch, which uses a dynamic graph.
At that stage we looked for a new DCGAN, now in Pytorch. However, we could not find the same one as in the paper and so we decided to implement it based on this pytorch example. It turned out that Spectral Normalization was already implemented in the latest version of Pytorch. Thus, we just had built our baseline!
Then, we needed to have the KID and the FID metrics also in Pytorch. We adapted this repository for the FID and implemented the KID ourself, by using Pytorch's inception.
Once having all implemented in Pytorch, it was easier to implement PA, and we did so.
Results
To run our experiments we used Google Cloud's Compute Engine. Each experiment was run in an individual instance with 4 CPU threads and 1 GPU.
We reproduced the results for the 4 datasets used in the paper: MNIST, FashionMNIST, Cifar10 and CelbA. In order to do that, the same SN-DCGAN architecture as in the paper was used.
For each dataset we run an experiment without PA as a baseline and also with PA to see if it improves. The results of those comparisons can be shown in the figures below.
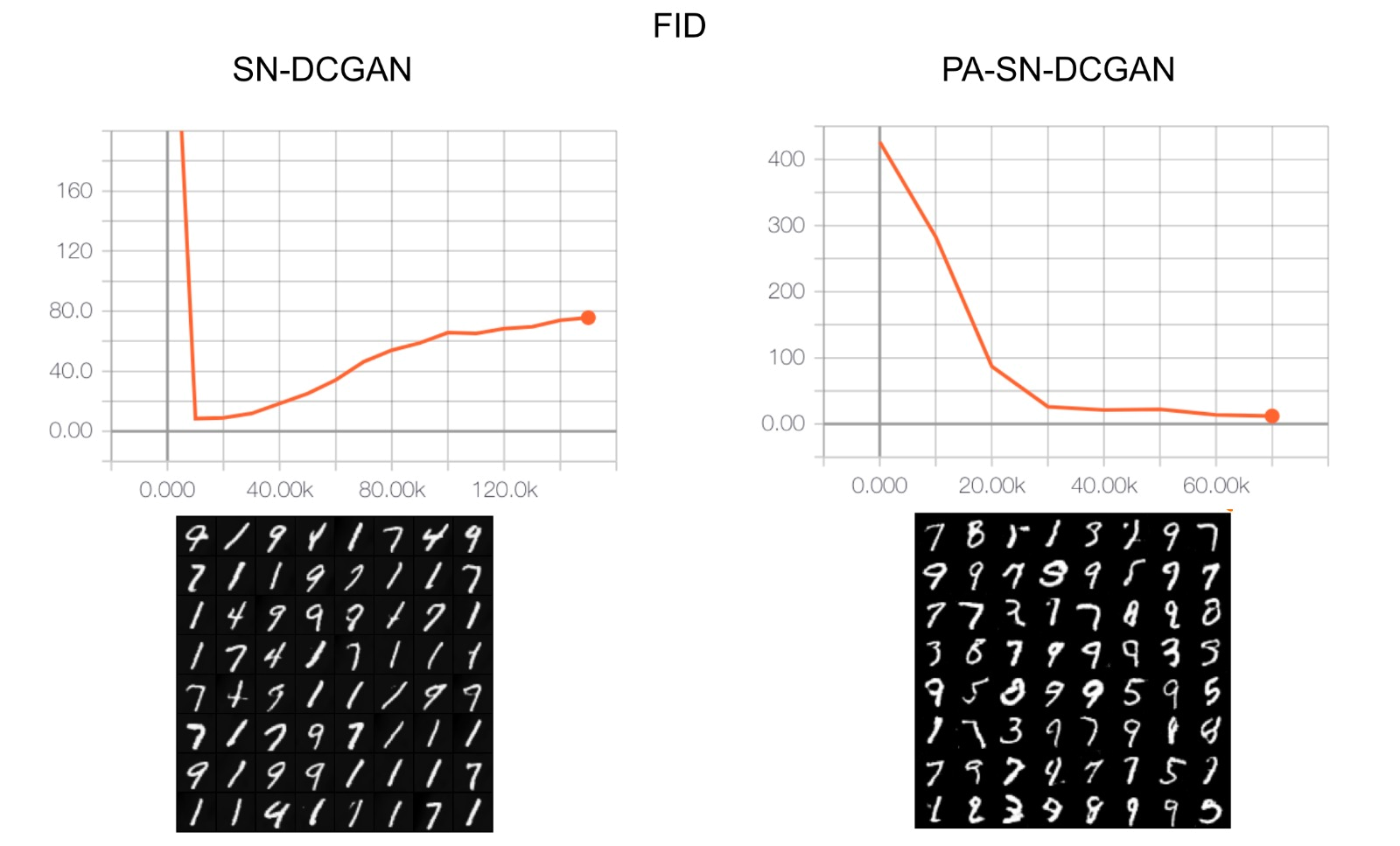
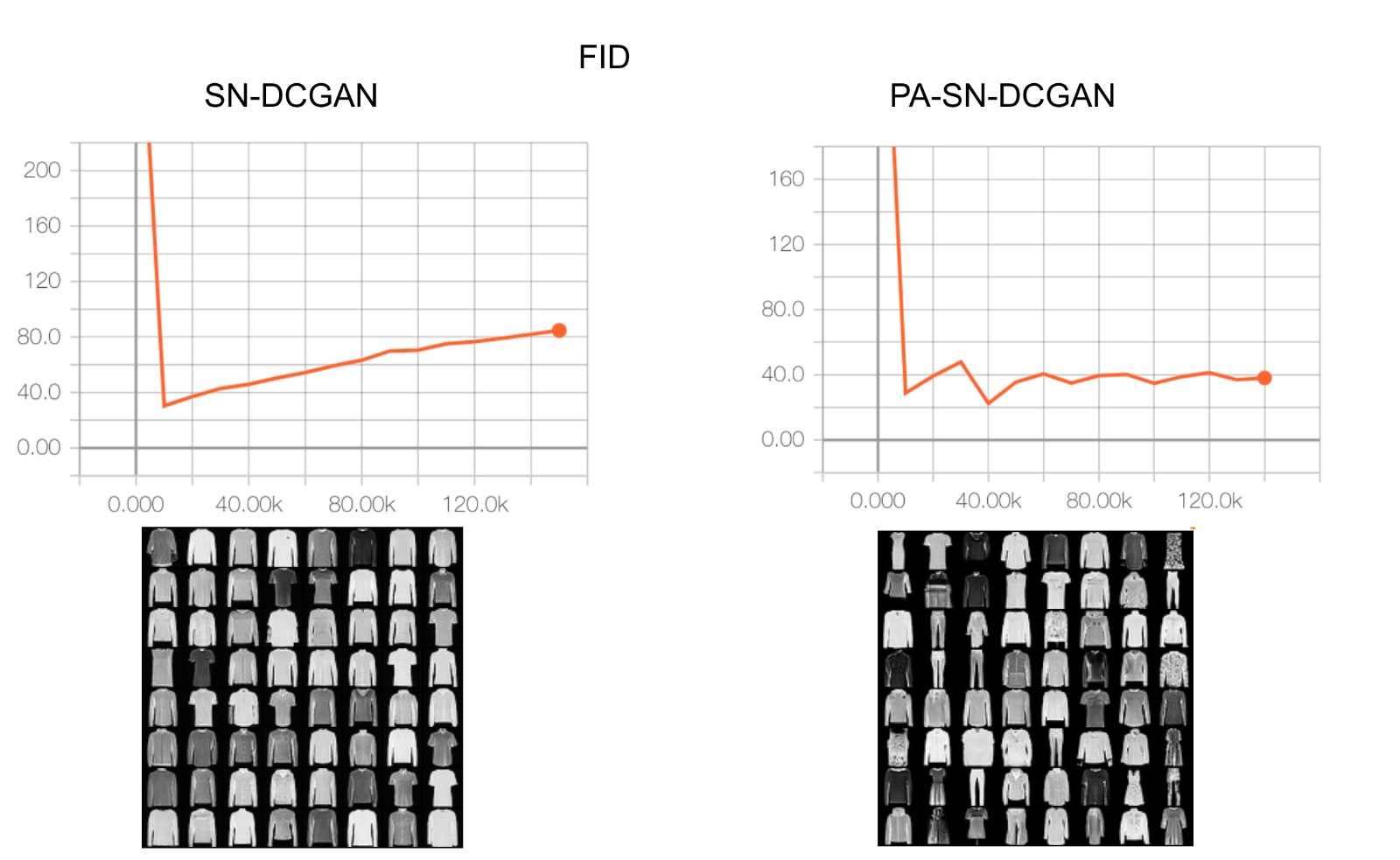
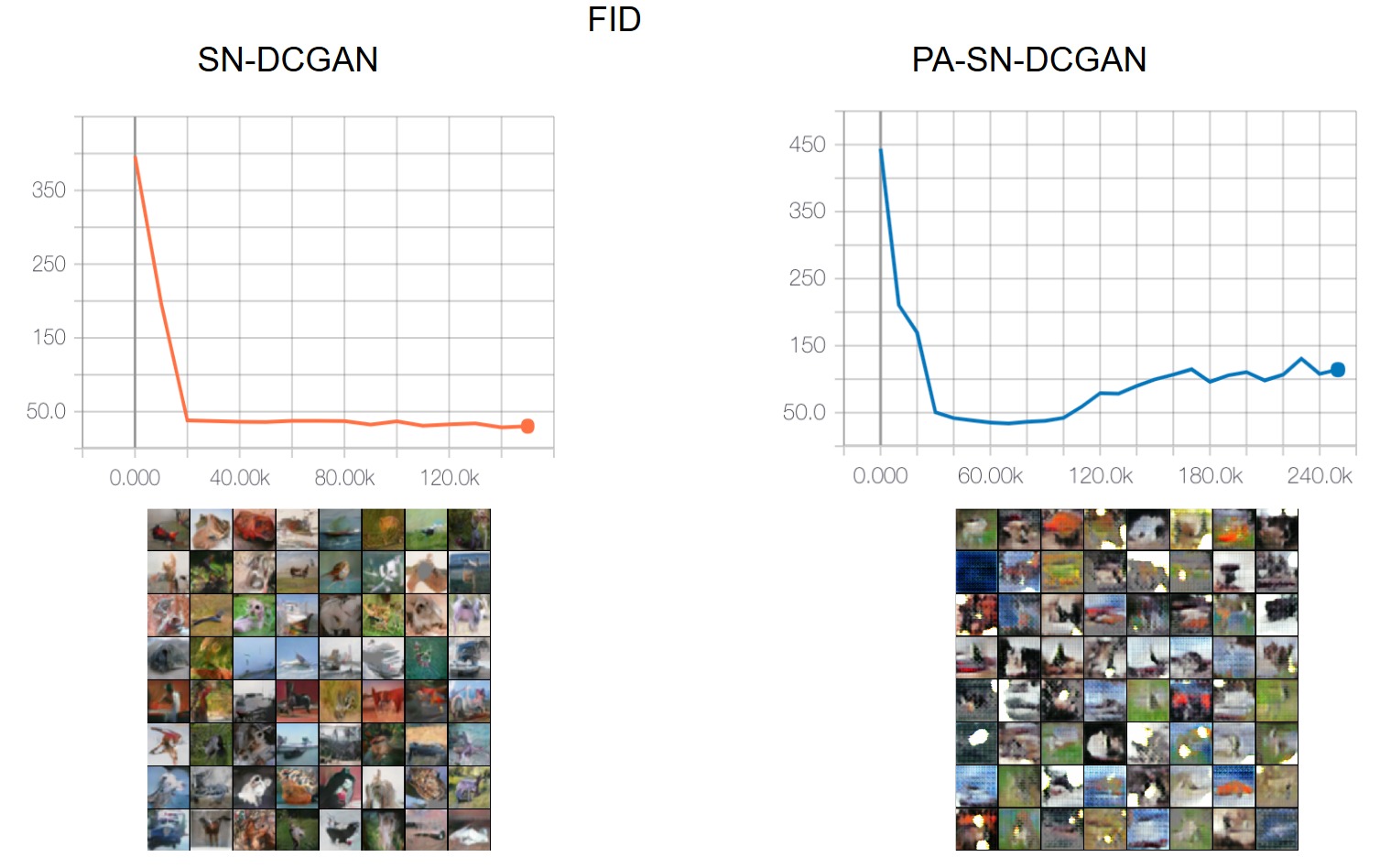
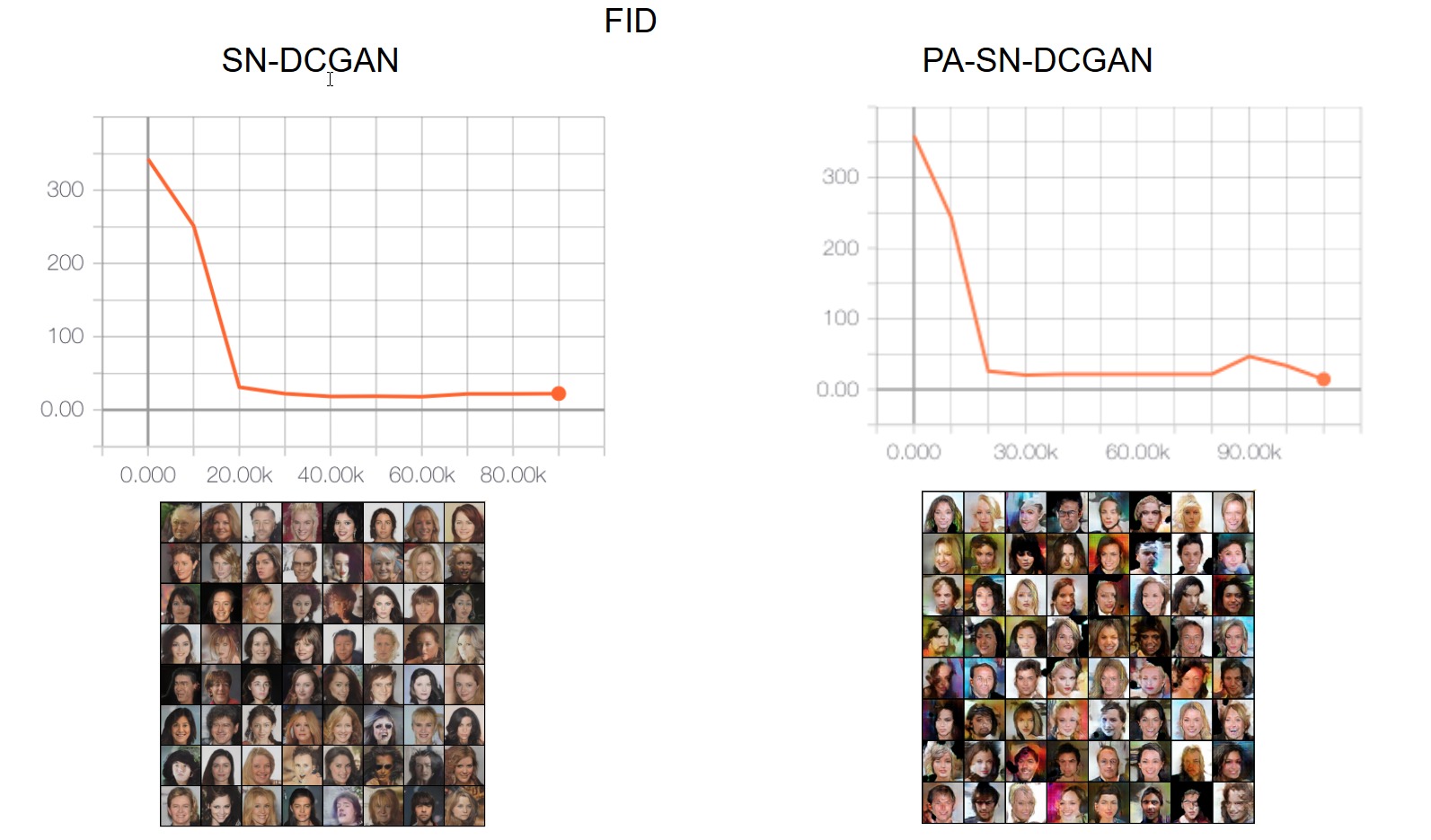
As you can see, for the first two datasets we have achieved the results from the paper. However, we show below that we could not reproduce the results for the two others yet. We are still running the experiments and we expect to have them all ready for the reproducibility challenge deadline. However, we have run into some difficulties when trying to find the right hyperparameters. We think that this is the reason why we have not been able to achieve the same results yet for the Cifar10 and the CelebA datasets, which are obviously more complex and thus, more "hyperparameter dependant". Some of the hyperparameter specifications that leads to confusions are:
- For the Cifar10 dataset, it is not clear whether they use a learning rate = 4e-4 or lr= 2e-4.
- It is clear on the paper that when achieving a new augmentation level the Generator’s learning rate must be decreased and, however, they do not state in the experiments section how they implemented it.
- We think there is an error in when they explain Progression scheduling. When they state the following sentence:
“If the current KID score is less than 5% of the average of the two previous ones attained at the same augmentation level, the augmentation is leveled up, i.e. L is increased by one”
we think they mean that the difference between the current KID and the mean of the last two, is the one which should be less than the 5% of the average of the two previous ones attained at the same augmentation level.
We plan to contact with the authors of the paper in order to clarify them.
CIFAR10
CELEBA
Code
This project was developed in Python 3.6.0, and it is implemented in PyTorch 0.4 and TensorFlow 1.4.
![]()

Thanks to
We would like to especially thank the support team at Xavier Giró and Noe Casas for guiding our project.
| We gratefully acknowledge the support of Google Cloud for the computational resources. |  |